# 哈希表介绍
coderwhy (opens new window) 哈希表是一种非常重要的数据结构, 几乎所有的编程语言都有直接或者间接的应用这种数据结构.
哈希表通常是基于数组进行实现的, 但是相对于数组, 它也很多的优势:
- 它可以提供非常快速的插入-删除-查找操作
- 无论多少数据, 插入和删除值需要接近常量的时间: 即O(1)的时间级. 实际上, 只需要几个机器指令即可
- 哈希表的速度比树还要快, 基本可以瞬间查找到想要的元素
- 哈希表相对于树来说编码要容易很多.
哈希表相对于数组的一些不足:
- 哈希表中的数据是没有顺序的, 所以不能以一种固定的方式(比如从小到大)来遍历其中的元素.
- 通常情况下, 哈希表中的key是不允许重复的, 不能放置相同的key, 用于保存不同的元素.
那么, 哈希表到底是什么呢?
- 似乎还是没有说它到底是什么.
- 这也是哈希表不好理解的地方, 不像数组和链表, 甚至是树一样直接画出你就知道它的结构, 甚至是原理了.
- 它的结构就是数组, 但是它神奇的地方在于对下标值的一种变换, 这种变换我们可以称之为哈希函数, 通过哈希函数可以获取到HashCode.
- 不着急, 我们慢慢来认识它到底是什么.
# 哈希函数
function hashFunc(str, max) {
// 1.初始化 hashCode 的值
var hashCode = 0;
// 2.秦九韶算法 / 霍纳算法
for (var i = 0; i < str.length; i++) {
hashCode = 37 * hashCode + str.charCodeAt(i);
}
// 3.取模运算
hashCode = hashCode % max;
return hashCode;
}
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 哈希表的简单实现
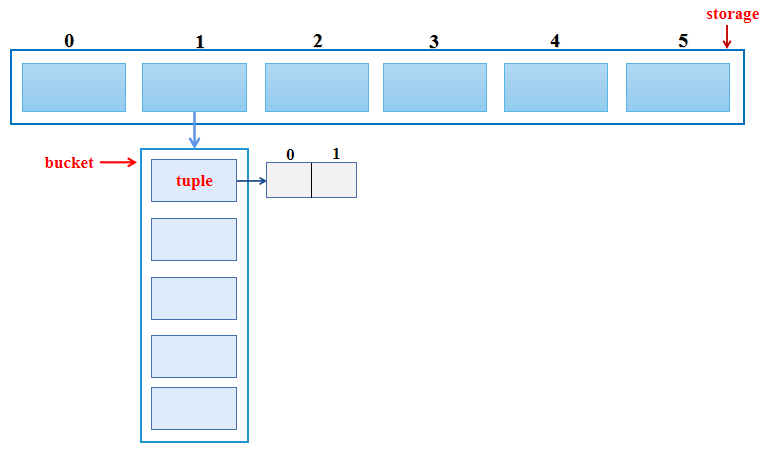
class HashTable {
constructor() {
// storage 作为数组,数组中存放相关的元素
this.storage = [];
this.count = 0;
this.limit = 8;
}
// 定义相关方法
// 哈希函数
hashFunc(str, max) {
let hashCode = 0;
for (let i = 0; i < str.length; i++) {
hashCode = 37 * hashCode + str.charCodeAt(i);
}
hashCode = hashCode % max;
return hashCode;
}
// 插入&修改数据
put(key, value) {
// 1.获取 key 对应的 index
// 1. 根据传入的 key 获取对应的 hashCode, 也就是数组的 index
let index = this.hashFunc(key, this.limit)
// 2.取出数组(也可以使用链表)
// 2. 从哈希表的index 位置中取出桶(另外一个数组)
let bucket = this.storage[index]
// 3.判断这个数组是否存在
/*
3. 查看上一步的 bucket 是否为 null
为null,表示之前在该位置没有放置过任何的内容,那么就新建一个数组[]
*/
if (bucket === undefined) {
// 3.1 创建桶
bucket = [];
this.storage[index] = bucket
}
// 4.判断是新增还是修改原来的值
/*
4. 查看是否之前已经放置过 key 对应的 value
如果放置过,那么就是依次进行替换操作,而不是插入新的数据
使用一个变量 override 来记录是否是修改操作
*/
let override = false;
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
if (tuple[0] === key) {
tuple[1] = value;
override = true;
}
}
// 5.如果是新增,前一步没有覆盖
/*
5. 如果不是修改操作,那么插入新的数据
在 bucket 中 push 新的 [key,value] 即可
注意:这里需要将 count+1,因为数据增加了一项
*/
if (!override) {
bucket.push([key, value]);
this.count++;
}
}
// 获取数据
get(key) {
// 1. 根据key 获取 hashCode [也就是index]
let index = this.hashFunc(key, this.limit);
// 2. 根据index 取出 bucket
let bucket = this.storage[index];
// 3. 如果bucket为null,说明这个位置之前并没有插入过数据
if (bucket == null) {
return null;
}
// 4. 如果有bucket,就遍历,并且如果找到,就将对应的 value 返回即可
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
if (tuple[0] === key) {
return tuple[1];
}
}
// 5. 没有找到,返回null
return null;
}
// 删除数据
delete(key) {
let index = this.hashFunc(key, this.limit);
let bucket = this.storage[index];
if (bucket == null) {
return null;
}
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
if (tuple[0] === key) {
bucket.splice(i, 1);
this.count--;
return tuple[1];
}
}
return null;
}
// 判断哈希表是否为空 isEmpty
isEmpty() {
return this.count === 0;
}
// 获取哈希表中数据的个数
size() {
return this.count;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
# 考虑扩容&质数问题
class HashTable {
constructor() {
// storage 作为数组,数组中存放相关的元素
this.storage = [];
this.count = 0;
this.limit = 8;
}
// 定义相关方法
// 哈希函数
hashFunc(str, max) {
let hashCode = 0;
for (let i = 0; i < str.length; i++) {
hashCode = 37 * hashCode + str.charCodeAt(i);
}
hashCode = hashCode % max;
return hashCode;
}
// 插入&修改数据
put(key, value) {
// 1.获取 key 对应的 index
// 1. 根据传入的 key 获取对应的 hashCode, 也就是数组的 index
let index = this.hashFunc(key, this.limit)
// 2.取出数组(也可以使用链表)
// 2. 从哈希表的index 位置中取出桶(另外一个数组)
let bucket = this.storage[index]
// 3.判断这个数组是否存在
/*
3. 查看上一步的 bucket 是否为 null
为null,表示之前在该位置没有放置过任何的内容,那么就新建一个数组[]
*/
if (bucket === undefined) {
// 3.1 创建桶
bucket = [];
this.storage[index] = bucket
}
// 4.判断是新增还是修改原来的值
/*
4. 查看是否之前已经放置过 key 对应的 value
如果放置过,那么就是依次进行替换操作,而不是插入新的数据
使用一个变量 override 来记录是否是修改操作
*/
let override = false;
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
if (tuple[0] === key) {
tuple[1] = value;
override = true;
}
}
// 5.如果是新增,前一步没有覆盖
/*
5. 如果不是修改操作,那么插入新的数据
在 bucket 中 push 新的 [key,value] 即可
注意:这里需要将 count+1,因为数据增加了一项
*/
if (!override) {
bucket.push([key, value]);
this.count++;
// 数组扩容
if (this.count > this.limit * 0.75) {
let primeNum = this.getPrime(this.limit * 2);
this.resize(primeNum);
}
}
}
// 获取数据
get(key) {
// 1. 根据key 获取 hashCode [也就是index]
let index = this.hashFunc(key, this.limit);
// 2. 根据index 取出 bucket
let bucket = this.storage[index];
// 3. 如果bucket为null,说明这个位置之前并没有插入过数据
if (bucket == null) {
return null;
}
// 4. 如果有bucket,就遍历,并且如果找到,就将对应的 value 返回即可
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
if (tuple[0] === key) {
return tuple[1];
}
}
// 5. 没有找到,返回null
return null;
}
// 删除数据
delete(key) {
let index = this.hashFunc(key, this.limit);
let bucket = this.storage[index];
if (bucket == null) {
return null;
}
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
if (tuple[0] === key) {
bucket.splice(i, 1);
this.count--;
//
if (this.limit > 8 && this.count < this.limit * 0.25) {
let primeNum = this.getPrime(Math.floor(this.limit / 2));
this.resize(primeNum);
}
}
return tuple[1];
}
return null;
}
// 判断哈希表是否为空 isEmpty
isEmpty() {
return this.count === 0;
}
// 获取哈希表中数据的个数
size() {
return this.count;
}
/*
哈希表扩容的实现
1. 先将之前数组保存起来,因为待会将 storage = []
2. 之前的属性值需要重置
3. 遍历所有的数据项,重新插入到哈希表中
*/
resize(newLimit) {
// 1. 先将之前数组保存起来,因为待会将 storage = []
let oldStorage = this.storage;
// 2. 之前的属性值需要重置
this.limit = newLimit;
this.count = 0;
this.strage = [];
// 3. 遍历所有的数据项,重新插入到哈希表中
oldStorage.forEach(bucket => {
if (bucket == null) {
return
}
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
this.put(tuple[0], tuple[1]);
}
}.bind(this))
}
// 判断是否是质数
isPrime(num) {
let temp = parseInt(Math.sqrt(num));
for (let i = 0; i < = temp; i++) {
if (num % i === 0) {
return false;
}
}
return true;
}
// 获取质数
getPrime(num) {
while (!isPrime(num)) {
num++;
}
return num;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
# 判断质数
// 补充
function isPrime(num) {
if (typeof num !== 'number' || num < 2) {
// 不是数字或者数字小于2
return false;
}
if (num === 2) { //2是质数
return true;
} else if (num % 2 === 0) { //排除偶数
return false;
}
var squareRoot = Math.sqrt(num);
//因为2已经验证过,所以从3开始;且已经排除偶数,所以每次加2
for (var i = 3; i <= squareRoot; i += 2) {
if (num % i === 0) {
return false;
}
}
return true;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 王争 18-22
# 19 散列表(中)
面试题目:如何设计一个工业级的散列函数?
思路:
- 何为一个工业级的散列表?
- 工业级的散列表应该具有哪些特性?
结合学过的知识,我觉的应该有这样的要求:
- 支持快速的查询、插入、删除操作;
- 内存占用合理,不能浪费过多空间;
- 性能稳定,在极端情况下,散列表的性能也不会退化到无法接受的情况。
方案:
- 如何设计这样一个散列表呢?
根据前面讲到的知识,我会从3个方面来考虑设计思路:
- 设计一个合适的散列函数;
- 定义装载因子阈值,并且设计动态扩容策略;
- 选择合适的散列冲突解决方法。
知识总结:
一、如何设计散列函数?
- 要尽可能让散列后的值随机且均匀分布,这样会尽可能减少散列冲突,即便冲突之后,分配到每个槽内的数据也比较均匀。
- 除此之外,散列函数的设计也不能太复杂,太复杂就会太耗时间,也会影响到散列表的性能。
- 常见的散列函数设计方法:直接寻址法、平方取中法、折叠法、随机数法等。
二、如何根据装载因子动态扩容?
- 如何设置装载因子阈值?
- 可以通过设置装载因子的阈值来控制是扩容还是缩容,支持动态扩容的散列表,插入数据的时间复杂度使用摊还分析法。
- 装载因子的阈值设置需要权衡时间复杂度和空间复杂度。如何权衡?如果内存空间不紧张,对执行效率要求很高,可以降低装载因子的阈值;相反,如果内存空间紧张,对执行效率要求又不高,可以增加装载因子的阈值。
- 如何避免低效扩容?分批扩容
- 分批扩容的插入操作:当有新数据要插入时,我们将数据插入新的散列表,并且从老的散列表中拿出一个数据放入新散列表。每次插入都重复上面的过程。这样插入操作就变得很快了。
- 分批扩容的查询操作:先查新散列表,再查老散列表。
- 通过分批扩容的方式,任何情况下,插入一个数据的时间复杂度都是O(1)。
三、如何选择散列冲突解决方法?
- 常见的2中方法:开放寻址法和链表法。
- 大部分情况下,链表法更加普适。而且,我们还可以通过将链表法中的链表改造成其他动态查找数据结构,比如红黑树、跳表,来避免散列表时间复杂度退化成O(n),抵御散列冲突攻击。
- 但是,对于小规模数据、装载因子不高的散列表,比较适合用开放寻址法。
# GitHub-最基本的散列表
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<script>
/*
最基本的散列表
*/
class HashTable {
constructor() {
this.table=[];
}
//散列函数
loseHashCode(key){
var hash=0;
//从ASCII表中查到的ASCII值加到hash中
for (var i=0;i<key.length;i++){
hash+=key.charCodeAt(i);
}
//为了得到比较小的数值,我们会用hash和任意数除余
return hash%37;
}
//向散列表增加一个新的项
put(key,value){
var position=this.loseHashCode(key);
console.log(position+'-'+key);
this.table[position]=value;
}
//根据键从散列表删除值
remove(key){
this.table[this.loseHashCode(key)]=undefined;
}
//返回根据键值检索到的特定的值
get(key){
console.log(this.table[this.loseHashCode(key)])
}
print(){
for (var i=0;i<this.table.length;++i){
if (this.table[i]!==undefined){
console.log(i+':'+this.table[i]);
}
}
}
}
var hash = new HashTable();
hash.put('Gandalf', 'gandalf@email.com');
hash.put('John', 'johnsnow@email.com');
hash.put('Tyrion', 'tyrion@email.com');
hash.remove('Gandalf')
hash.get('Gandalf')
hash.get('Tyrion')
hash.print()
//
</script>
</body>
</html>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# GitHub-
/****
* 带碰撞处理的Hash表
* 实际上在js中,单独实现一个Hash表感觉不是很有实用价值
* 如果需要通常是直接将Object,Map,Set来当Hash表用
*
* 总结:
* 我写的这个实现把store 从Object换成Array不会有运行性能上的区别
* 把hash函数改成生成一定范围的值的类型,然后初始化一个指定长度的数组因该会有一定的性能提升
* 把store换成Map,然后修改相关实现会获得飞越性的提升,因为在js中Map的实现对这种类型的操作做了优化
*/
class HashTable {
constructor() {
//创建一个没有原型链的对象
this.store = Object.create(null);
}
/**
* Donald E. Knuth在“计算机编程艺术第3卷”中提出的算法,主题是排序和搜索第6.4章。
* @param {*} string
* 翻译自别的语言的实现
* 需要注意的是由于js中没有int类型,number是dobule的标准实现
* 所以返回前的位运算实际和本来的设想不一致,也就是同样的实现,在别的语言中返回可能不同
*/
hash(string) {
let len = string.length;
let hash = len;
for (let i = 0; i < len; i++) {
hash = ((hash << 5) ^ (hash >> 27)) ^ string.charCodeAt(i);
}
return hash & 0x7FFFFFFF;
}
isCresh(item) {
return Object.prototype.toString.call(item) === "[object Map]"
}
/**
* 约定item必须要有key
* @param {*} item
*/
put(item) {
if (typeof item.key !== 'string') {
throw 'item must have key!'
}
let hash = this.hash(item.key);
//碰撞处理
let cresh = this.store[hash];
if (cresh) {
if (cresh.key === item.key) {
this.store[hash] = item;
return
}
if (!this.isCresh(cresh)) {
this.store[hash] = new Map();
}
this.store[hash].set(item.key, item);
} else {
this.store[hash] = item;
}
}
get(key) {
let hash = this.hash(key);
let value = this.store[hash] || null;
if (this.isCresh(value)) {
return value.get(key);
} else {
return value
}
}
remove(key) {
let hash = this.hash(key);
let value = this.store[hash];
if (!value) {
return null;
}
if (this.isCresh(value)) {
value.delete(key);
} else {
delete this.store[hash];
}
}
clear() {
this.store = {};
}
print() {
let values = Object.values(this.store);
values.forEach(element => {
if (this.isCresh(element)) {
element.forEach(item => {
console.log(item);
});
} else {
console.log(element)
}
});
}
}
/**
* 相比使用Object和Array做store 运行时的性能提升了三分之一
* 但当前这种用法没有直接使用Map方便,而且直接使用Map会快的多
*/
class HashTableBaseMap {
constructor() {
this.store = new Map();
}
/**
* Donald E. Knuth在“计算机编程艺术第3卷”中提出的算法,主题是排序和搜索第6.4章。
* @param {*} string
* 翻译自别的语言的实现
* 需要注意的是由于js中没有int类型,number是dobule的标准实现
* 所以返回前的位运算实际和本来的设想不一致,也就是同样的实现,在别的语言中返回可能不同
*/
hash(string) {
let len = string.length;
let hash = len;
for (let i = 0; i < len; i++) {
hash = ((hash << 5) ^ (hash >> 27)) ^ string.charCodeAt(i);
}
return hash & 0x7FFFFFFF;
}
isCresh(item) {
return Object.prototype.toString.call(item) === "[object Map]"
}
/**
* 约定item必须要有key
* @param {*} item
*/
put(item) {
if (typeof item.key !== 'string') {
throw 'item must have key!'
}
let hash = this.hash(item.key);
//碰撞处理
let cresh = this.store.get(hash);
if (cresh) {
if (cresh.key === item.key) {
this.store.set(hash, item);
return
}
if (!this.isCresh(cresh)) {
this.store[hash] = new Map();
}
this.store[hash].set(item.key, item);
} else {
this.store.set(hash, item);
}
}
get(key) {
let hash = this.hash(key);
let value = this.store.get(hash);
if (this.isCresh(value)) {
return value.get(key);
} else {
return value
}
}
remove(key) {
let hash = this.hash(key);
let value = this.store.get(hash);
if (!value) {
return null;
}
if (this.isCresh(value)) {
value.delete(key);
} else {
this.store.delete(hash)
}
}
clear() {
this.store = {};
}
print() {
this.store.forEach(element => {
if (this.isCresh(element)) {
element.forEach(item => {
console.log(item);
});
} else {
console.log(element)
}
});
}
}
/**
* 基础测试
*/
function baseTest() {
let hashTable = new HashTable();
for (let i = 0; i < 10; i++) {
hashTable.put({
key: 'test' + i,
value: 'some value' + i
});
}
console.log('step1:')
//随机获取5次
for (let j = 0; j < 5; j++) {
let key = 'test' + Math.floor(Math.random() * 10);
console.log(key);
console.log(hashTable.get(key))
}
//获得一次空值
console.log('get null:', hashTable.get('test10'))
//修改一次值
hashTable.put({
key: 'test1',
value: 'change'
});
//删除一次值
hashTable.remove('test2');
console.log('step2:')
//输出修改后所有的
hashTable.print();
}
/**
* 有序key存取,性能测试
*/
function ordKeyTest() {
let length = 1000000;
console.time('create')
let hashTable = new HashTable();
for (let i = 0; i < length; i++) {
//24位长度有序key
hashTable.put({
key: 'someTestSoSoSoSoLongKey' + i,
value: 'some value' + i
});
}
console.timeEnd('create')
let get = 100000;
console.time('get')
for (let j = 0; j < get; j++) {
let key = 'test' + Math.floor(Math.random() * 999999);
hashTable.get(key)
}
console.timeEnd('get')
}
/**
* 无序key性能测试
* 这个查找稍微有点不准,会有一定量随机字符串重复
* 实际结果,创建没有区别,大数据量下由于无序key有一些会碰撞,get的总体用的时间会多不少。
*/
function randKeyTest() {
let length = 1000000;
let keyList = [];
for (let i = 0; i < length; i++) {
keyList.push(randomString());
}
console.time('create')
let hashTable = new HashTable();
for (let i = 0; i < length; i++) {
hashTable.put({
key: keyList[i],
value: 'some value' + i
});
}
console.timeEnd('create')
let get = 100000;
console.time('get')
for (let j = 0; j < get; j++) {
let key = keyList[Math.floor(Math.random() * 999999)];
hashTable.get(key)
}
console.timeEnd('get')
}
/**
* 直接使用Object的性能测试
* 有序就不测了,估计不会有区别,只看不使用hash的无序key
* 结果:想达到同样的结果创建会比hash后的慢接近四分之三,获取用时差不多
*/
function randKeyTestFromObj() {
let length = 1000000;
let keyList = [];
for (let i = 0; i < length; i++) {
keyList.push(randomString());
}
console.time('create')
let hashTable = {};
for (let i = 0; i < length; i++) {
let key = keyList[i];
hashTable[key] = {
key: key,
value: 'some value' + i
}
}
console.timeEnd('create')
let get = 100000;
console.time('get')
for (let j = 0; j < get; j++) {
let key = keyList[Math.floor(Math.random() * 999999)];
hashTable[key]
}
console.timeEnd('get')
}
/**
* 直接使用Map的性能测试
* 结果:创建用时差不多,但是获取快了一个数量级(十倍不止)
*/
function randKeyTestFromMap() {
let length = 1000000;
let keyList = [];
for (let i = 0; i < length; i++) {
keyList.push(randomString());
}
console.time('create')
let hashTable = new Map();
for (let i = 0; i < length; i++) {
let key = keyList[i];
hashTable.set(key, {
key: key,
value: 'some value' + i
})
}
console.timeEnd('create')
let get = 100000;
console.time('get')
for (let j = 0; j < get; j++) {
let key = keyList[Math.floor(Math.random() * 999999)];
hashTable.get(key);
}
console.timeEnd('get')
}
//生成指定长度的字符串
function randomString(len) {
len = len || 24;
var chars = 'ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678';
var maxPos = chars.length;
var pwd = '';
for (i = 0; i < len; i++) {
pwd += chars.charAt(Math.floor(Math.random() * maxPos));
}
return pwd;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340